La recursión o recursividad, en pocas palabras, es una técnica de resolución de problemas en la que la solución depende de la solución a un caso más pequeño del mismo problema. Es decir, la solución depende de la propia solución. Confuso, ¿verdad?
Un ejemplo muy intuitivo es la solución de la operación factorial. El factorial se define para un entero positivo $n$ como el producto de todos los enteros entre 1 y $n$. Por ejemplo, para $n = 5$:
$$5! = 1\cdot 2\cdot 3\cdot 4\cdot 5 = 120$$Sin embargo, aquí podemos observar el primer ejemplo de recursión, pues $5!$ no es más que el producto de $4!$ por 5:
$$5! = 4!\cdot 5 = \underbrace{1\cdot 2\cdot 3\cdot 4}_{4!}\cdot 5$$Y esto se puede generalizar fácilmente a cualquier valor $n\in\mathbb{N}$ diferente de cero sin darle muchas vueltas:
$$n! = (n-1)!\cdot n$$El caso base #
Obtengamos ahora la solución de $5!$ haciendo todos los pasos:
$$5! = (5-1)!\cdot 5 = 4!\cdot 5$$ $$4! = (4-1)!\cdot 4 = 3!\cdot 4$$ $$3! = (3-1)!\cdot 3 = 2!\cdot 3$$ $$2! = (2-1)!\cdot 2 = 1!\cdot 2$$ $$1! = (1-1)!\cdot 1 = 0!\cdot 1$$Un momento. ¿Qué pasaría si seguimos la secuencia? Si aplicamos la fórmula general de $n!$ para $n=0$, obtenemos un resultado incorrecto por dos razones:
- El factorial solo está definido para enteros positivos, por lo que no existe $(0-1)!$.
- Al multiplicar por cero, el resultado se anula, mientras que, por convenio, $0! = 1$.
¿Cómo evitamos esta situación? En estos casos tenemos que definir en nuestro algoritmo recursivo un caso base que detenga la recursión. De otro modo, el proceso se seguiría repitiendo infinitamente, o hasta que se agote la memoria del programa.
Para el factorial, el caso base podría ser que, cuando $n=0$, el resultado de la función factorial sea 1. Así evitaríamos pasar a valores negativos, donde la operación no está definida.
Ahora podemos implementar una función recursiva factorial que tome como argumento un entero positivo $n$ y devuelva el resultado de $n!$:
unsigned factorial (unsigned n) {
if (n == 0) return 1; // Caso base
return factorial(n-1) * n; // Resto de casos
}
Otro ejemplo: Fibonacci #
Otro de los ejemplos más sencillos de recursión es la sucesión de Fibonacci, que empieza así:
$$1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, \dots$$donde un valor de la serie es el resultado de los dos inmediatamente anteriores. La fórmula general para calcular el enésimo valor de la serie es:
$$F_n = F_{n-1} + F_{n-2}$$Así, por ejemplo, el quinto valor sería $2+3=5$. Nuevamente, si aplicamos esta fórmula indiscriminadamente, pronto nos encontraremos con que, al llegar al inicio de la secuencia, carecemos de valores suficientes para realizar la suma. En este caso, definimos que los dos primeros valores de la secuencia tienen valor 1, de modo que los sucesivos sí tengan respuesta.
Es este el caso base de la recursión de Fibonacci. Como norma general, hay que mirar hacia los extremos para encontrar el caso base de un algoritmo.
Enésimo valor de la sucesión de Fibonacci #
Un problema típico para practicar el concepto de recursión consiste en, dado un entero positivo $n$ diferente de cero, encontrar el $n$-ésimo valor de la serie anterior. A continuación se presenta una posible implementación de una función recursiva que resuelva el problema:
unsigned fibonacci (unsigned n) {
if (n <= 2) return 1;
return fibonacci(n-1) + fibonacci(n-2);
}
Complejidad #
Uno de los inconvenientes de la recursión es la elevada complejidad espacial y temporal del método. En general, resulta ser un método bastante sencillo y útil para problemas pequeños, y también cuando se utiliza en combinación con otras técnicas como la programación dinámica, que ayudan a reducir significativamente el árbol de llamadas.
Por ejemplo, la función fibonacci anterior tiene una complejidad fija de $O(2^n)$, que, como podemos ver en esta gráfica, no es muy eficiente que digamos. Esto ocurre debido a que en cadad paso se generan dos llamadas a la función, dando lugar a un árbol binario de $2^n$ elementos. Hay que tener esto muy en cuenta a la hora de lidiar con la complejidad espacial, ya que por cada llamada a la función se añade un nuevo elemento al call stack, que puede desbordarse fácilmente si se utiliza indiscriminadamente.
Por ello, muchos algoritmos recursivos se pueden implementar de forma más eficiente siguiendo una estrategia iterativa. Por ejemplo, la función fibonacci anterior se puede simplificar en un único bucle for y dos variables:
int n, a = 1, b = 1;
cin >> n;
for (int i = 2; i <= n; i++) {
swap(a, b); // intercambia los valores de a y b
b += a;
}
cout << b << '\n';
Generación de subconjuntos #
Algunas de las aplicaciones más habituales de la recursión son la generación de subconjuntos y permutaciones (esta última la veremos en el siguiente apartado), y sirven de base para muchos problemas de diferente índole.
Tomemos el primero de los casos. Tenemos un conjunto $S$ con $n$ elementos —tiene cardinalidad $n$—, a partir del que se puede generar un subconjunto cualquiera $Q$ de entre 0 y $n$ elementos, conteniendo únicamente valores que ya pertenezcan previamente a $S$. Así, los subconjuntos posibles de $\{a, b, c\}$ son:
$$\{\emptyset\}, \{a\}, \{b\}, \{c\}, \{a, b\}, \{a, c\}, \{b, c\}, \{a, b, c\}$$Nota: consideramos que dos conjuntos $\{a, b\} y \{b, a\}$ son iguales.
A grandes rasgos, la generación de subconjuntos consiste en interar a través del conjunto original y, en cada elemento, decidir si incluirlo en el subconjunto o no. De este modo, a cada paso se abre un árbol de posibilidades que aumenta exponencialmente en tamaño a medida que avanzamos en el conjunto. El resultado final es un árbol binario como este:
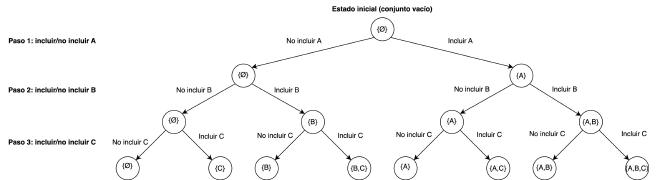
El número de pasos (la longitud del camino desde la raíz del árbol hasta una de las hojas) se corresponde con el número de elementos del conjunto inicial, $n$.
A continuación se presenta una posible implementación de una función recursiva que genere todos los subconjuntos de un vector v:
#include <bits/stdc++.h>
using namespace std;
void generate(int idx, const vector<int>& v, vector<int>& subset) {
if (idx == v.size()) {
// Caso base (hemos procesado todos los elementos de v)
// Imprimimos el subconjunto actual:
if (subset.empty()) cout << "[]\n";
for (int i = 0; i < subset.size(); i++)
cout << ((i == 0) ? "[" : "") << subset[i]
<< ((i == subset.size()-1) ? "]\n" : ", ");
} else {
// Incluimos el elemento actual en el subconjunto (derecha)
subset.push_back(v[idx]);
generate(idx+1);
// No incluimos el elemento actual (camino de la izquierda)
subset.pop_back();
generate(idx+1);
}
}
int main () {
const vector<int> v = {1, 2, 3}; // Conjunto original
vector<int> subset; // Subconjunto inicialmente vacío
generate(0, v, subset);
return 0;
}
Y al ejecutar el código anterior, obtenemos la siguiente salida:
[1, 2, 3]
[1, 2]
[1, 3]
[1]
[2, 3]
[2]
[3]
[]
La función que hemos implementado recorre el árbol de la imagen anterior de derecha a izquierda. En cada llamada se bifurcan dos ramas:
- En la primera se incluye el elemento en la posición
idxdel conjunto original en el subconjunto nuevo. Entonces, se vuelve a llamar a la funcióngenerateconidx+1para realizar el mismo proceso sobre el siguiente elemento. - En la segunda rama se elimina (no se incluye) el elemento en la posición
idxdel conjunto original. De nuevo, se vuelve a llamar a la función conidx+1para procesar el siguiente elemento.
La recursión se detiene cuando idx es igual al tamaño del vector, es decir, cuando hemos procesado todos los elementos del conjunto original (caso base).
Generación de permutaciones #
Este segundo caso sigue una estrategia muy similar al de la generación de subconjuntos, con la diferencia de que, dado un conjunto $S$ con cardinalidad $n$, tenemos que encontrar las $n!$ posibilidades de ordenar los elementos de $S$ de forma distinta. La razón por la que son $n!$ combinaciones en vez de $2^n$ es que ahora no estamos realizando una decisión binaria (incluir el elemento $x$, o no incluirlo), sino que:
- En el paso 1, decidimos cuál de los $n$ elementos del conjunto colocamos en primera posición.
- En el paso 2, decidimos cuál de los $n-1$ elementos restantes del conjunto colocamos en segunda posición.
- En el paso 3, tendremos $n-2$ elementos restantes, y así sucesivamente, hasta que solo tengamos una posibilidad.
De este modo, el árbol de decisiones quedaría:
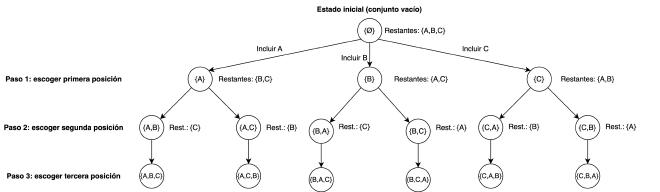
Para implementar la función recursiva, además del vector con el conjunto original y otro para almacenar la permutación actual, debemos mantener un tercer array booleano de $n$ elementos que nos permitirá saber si el elemento en una posición cualquiera $i$ ya forma parte de la permutación actual o no (porque un mismo elemento no puede aparecer más de una vez).
En vez de realizar dos llamadas dentro de la función como en el caso anterior, ahora utilizaremos un bucle for que se encargará de llamar de nuevo a la función incluyendo en cada paso cada uno de los elementos restantes del conjunto original.
#include <bits/stdc++.h>
using namespace std;
void generate(const vector<int>& v, vector<int>& permutation, vector<bool>& chosen) {
if (permutation.size() == v.size()) {
// Caso base (hemos incluido todos los elementos de v)
// Imprimimos la permutación actual:
for (int i = 0; i < permutation.size(); i++)
cout << ((i == 0) ? "[" : "") << permutation[i]
<< ((i == permutation.size()-1) ? "]\n" : ", ");
} else {
for (int i = 0; i < v.size(); i++) {
if (chosen[i]) continue;
chosen[i] = true;
permutation.push_back(v[i]); // Incluimos el elemento actual
generate(v, permutation, chosen);
chosen[i] = false;
permutation.pop_back(); // Restablecemos el estado anterior
}
}
}
int main () {
const vector<int> v = {1, 2, 3}; // Conjunto original
vector<int> permutation; // Permutación inicialmente vacía
vector<bool> chosen(v.size(), false);
generate(v, permutation, chosen);
return 0;
}
En la salida de este código obtenemos las 6 posibles permutaciones del conjunto $\{1, 2, 3\}$:
[1, 2, 3]
[1, 3, 2]
[2, 1, 3]
[2, 3, 1]
[3, 1, 2]
[3, 2, 1]
El método next_permutation
#
Afortunadamente, la librería estándar de C++ ya incluye una función que permite generar todas las permutaciones de un vector en orden lexicográfico:
#include <bits/stdc++.h>
using namespace std;
int main () {
vector<int> v = {1, 2, 3};
do {
for (int i = 0; i < v.size(); i++)
cout << ((i == 0) ? "[" : "") << v[i]
<< ((i == v.size()-1) ? "]\n" : ", ");
} while (next_permutation(v.begin(), v.end()));
return 0;
}
Este código devuelve la misma salida que la implementación anterior, y resulta mucho más sencillo de entender. No obstante, hay que tener en cuenta que next_permutation modifica el orden de los elementos del vector, por lo que este no puede ser constante, como hacíamos antes.
Si necesitamos mantener el orden original, es conveniente realizar una copia auxiliar del vector antes de generar las permutaciones.
Problemas #
Aquí tienes algunos problemas para practicar antes de la próxima sección.
-
Permutations (CSES 1070, solución).
Explicación (spoiler!)
Una solución intuitiva podría ser utilizar una de las implementaciones anteriores para generar permutaciones de los enteros $1, 2, \dots, n$ hasta que encontremos una permutación que cumpla las restricciones (que no tenga dos elementos adyacentes $a_i$ y $a_{i+1}$ tal que $|a_i-a_{i+1}| = 1$).
No obstante, debido a los problemas de complejidad que hemos comentado anteriormente, esta opción se vuelve rápidamente inviable a medida que aumenta el valor de $n$. Teniendo en cuenta que el valor máximo de $n$ para este problema es $10^6$, este último caso nos daría un total de $10^6!$ permutaciones, que supera en cientos de miles de trillones el número de átomos en el universo observable (y aún me quedo corto).
Para sortear este pequeño inconveniente, tenemos que darnos cuenta de que existe una solución para cualquier valor de $n$ diferente de 2 y 3 (en el caso del 2, las permutaciones
2 1y1 2son inválidas; y para el 3:1 2 3,1 3 2,2 1 3,2 3 1,3 1 2y3 2 1son todas inválidas). Luego, los casos $n=1$ y $n=4$ tienen una única solución (1y3 1 4 2, respectivamente). Podemos construir la solución:-
Si $n=1$, la solución es
1. -
Si $n=2$ o $n=3$, no existe solución.
-
Si $n=4$, la solución es
3 1 4 2. -
Para $n>4$, podemos simplemente escribir primero los impares desde 1 hasta $n$, seguidos de los pares entre 2 y $n$. De este modo garantizamos que la distancia mínima entre dos valores adyacentes sea de dos unidades.
Por ejemplo, para $n=7$:
1 3 5 7 2 4 6.
-
-
Two Sets (CSES 1092, solución).
Explicación (spoiler!)
Este problema tiene un planteamiento similar al anterior en cuanto a que la solución intuitiva consiste en realizar todas las particiones posibles del conjunto de los enteros $1, 2, \dots, n$ hasta que encontremos una que satisfaga los requisitos. De nuevo, esta no es una solución óptima, debido a que el número de particiones posibles aumentaría exponencialmente a medida que aumenta el valor de $n$.
En cambio, podemos realizar varias comprobaciones para agilizar mucho el proceso:
-
Existirá una solución si y solo si el resultado de la suma de los valores $1, 2, \dots, n$ es par (si es impar, no se podrá distribuir equitativamente sin recurrir a valores fraccionarios).
-
Si $n$ es divisible entre 4, podemos separar los $n$ valores en intervalos de 4 y añadir, a uno de los subconjuntos, los dos valores a los extremos del intervalo, y al otro subconjunto los dos valores intermedios.
Ejemplo: para $n=4$, los subconjuntos serían $\{1, 4\}$ y $\{2, 3\}$, sumando ambos 5.
-
Si $n$ no es divisible entre 4, pero $n+1$ sí (es decir, si $n\bmod 4 = 3$), inicializaremos los subconjuntos con los valores $\{1, 2\}$ y $\{3\}$, y realizaremos el mismo proceso que para $n$ divisible entre 4, pero a partir de 4, en vez de 1.
Para calcular de manera eficiente la suma de los valores $1, 2,\dots, n$ podemos recurrir al mismo principio que utilizamos en el primer problema de esta serie, Missing Number. Así, sabemos que la suma tiene como resultado:
$$\sum_{i = 1}^ni = \frac{n(n+1)}{2}$$La razón por la que no hay casos con solución para los que $n\bmod 4 = 1$ o $n\bmod 4 = 2$ es que para dichos valores de $n$, el resultado de $\frac{n(n+1)}{2}$ será impar debido a que solo hay un único 2 en la factorización de la expresión $n(n+1)$, que se elimina posteriormente al dividir entre 2.
-
-
Little Elephant and Function (Codeforces 221A, solución).
Explicación (spoiler!)
La función recursiva $f(x)$ descrita en el enunciado, lo único que hace es mover el primer elemento de la secuencia a la última posición. Por tanto, la solución para todos los casos es:
$$n, 1, 2, 3, \dots, n-1$$De modo que, tras llamar a la función recursiva, quede así:
$$1, 2, 3, \dots, n-1, n$$
